

Highly Available Keycloak on Kubernetes
Maintaining state while adding replicas

DevOps Solution Architect focusing in AWS and all things Automation.
GitOps and ArgoCD fanboy, lover of all things Kubernetes
Introduction
Keycloak is one of the most common Identity and Access Management (IAM) tools that we see customers using. It's free, open-source, and has somewhat become an industry standard for clients that want their own hosted IAM versus using a SaaS offering like Okta or Azure AD for their Single Sign On (SSO) solution.
Self-hosted products are great, but sometimes it means that you need to spend additional time configuring and deploying the product to your own specific needs. While working with a client, one of their major tasks was getting Keycloak to be deployed in a highly available (HA) manner inside of their Kubernetes clusters. If you're experienced in Kubernetes, you might think this should be as simple as editing your Keycloak deployment spec to have replicas: 2. As you'll learn here, sadly there is more configuration necessary, and not the best documentation on how exactly to achieve this.
The Problem
Out of the box, Keycloak isn't configured to be deployed with multiple replicas in any environment let alone a Kubernetes cluster. By default, Keycloak assumes it's a standalone instance without any knowledge of other Keycloak instances that may be running around it. You set up a backend database that stores user information as well as data about your organization, and you set Keycloak to pull from it. If an instance of Keycloak (a pod in our case) goes down, Kubernetes spins a new one up and it retrieves the information from the database as normal and keeps on going.
However, our client wanted Keycloak to be Highly Available, with two or more Keycloak pods running at a time. They wanted this for scalability as well as not having to wait for a new Keycloak pod to start again if something were to happen to the old one. Easy right? Let's edit our deployment.yaml file to create a second Keycloak pod.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: keycloak
spec:
replicas: 2
serviceName: keycloak
selector:
matchLabels:
app: keycloak
...
Now they'll both connect to the Postgres database for the data they need and we can wipe our hands clean of this. Easy win! Wrong.
While most data is stored in your backend database, there are a couple of pieces of important data that are stored in an internal Infinispan cache inside each pod. Important data like user authentication sessions. With our load balancer in front, if a user that was already authenticated was somehow directed to the other Keycloak pod, that pod would have no authentication data for them and force them to log in again. This would introduce a lot of confusion to their customers who are just trying to use their SaaS services and are having to constantly log in over and over again.
If your load balancer allows it, we could enable sticky sessions to stop this from happening, but the problem is reintroduced if the pod our traffic was constantly being sent through went down. When the new pod comes up, it won't have any of that internal cache data, and users will need to log in yet again.
The Solution
After researching, we found that Keycloak offers what they refer to as a Standalone Clustered mode. Essentially, this allows multiple Keycloak instances to be made aware of each other so that the Infinispan Cache can be retrieved and shared by multiple instances of Keycloak. Infinispan has multiple ways of doing this, but for this blog, we're going to describe DNS_PING .
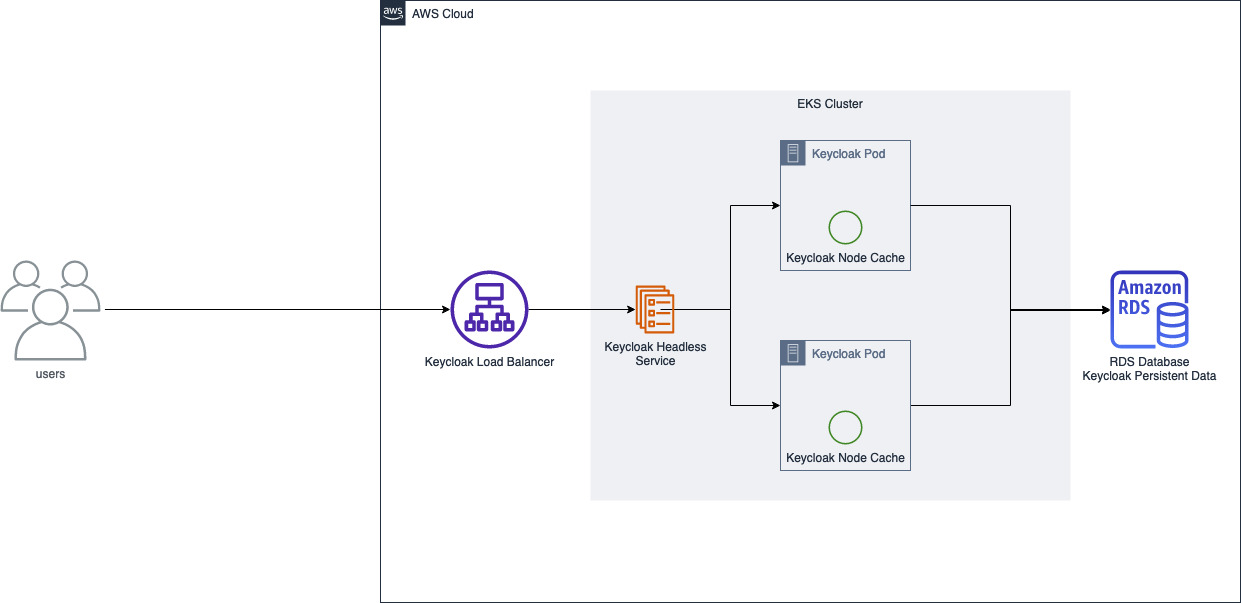
Using DNS_PING we can supply Keycloak with any DNS record that resolves to a Keycloak instance. Keycloak then ensures it can connect to the supplied instances and knows that these are now "clustered". On Kubernetes, we luckily have an easy way to get a DNS record that resolves to all of our pods, a headless service.
By setting ClusterIP: None in a Kubernetes Service resource, we get what is known as a Headless Service. When a request hits this service, the response is an A record to each pod that is backing the service at that moment. Sounds perfect for finding each Keycloak Pod!
To do this, we had to edit our helm chart a bit:
Create the Headless Service
Use a StatefulSet instead of a Deployment (Keycloak has a hard limit of 23 characters for DNS Names)
Set Environment Variables in Keycloak to configure it to use
DNS_PINGto find all Keycloak instancesRun a startup script to set Cache Owners at node startup and mount it into the Keycloak pods to run at startup inside of
/opt/jboss/startup-scripts/using a configmap
That turns our resource files into this:
# headless-svc.yml
---
apiVersion: v1
kind: Service
metadata:
name: keycloak-headless
namespace: keycloak
spec:
type: ClusterIP
clusterIP: None
selector:
app: keycloak
ports:
- protocol: TCP
port: 80
targetPort: 80
# statefulSet.yaml
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: keycloak
spec:
replicas: 2
serviceName: keycloak-headless
selector:
matchLabels:
app: keycloak
template:
metadata:
labels:
app: keycloak
spec:
containers:
- image: "{{ .Values.image }}:{{ .Values.tag }}"
name: keycloak
env:
# Enable DNS_PING to find other Pods
- name: JGROUPS_DISCOVERY_PROTOCOL
value: dns.DNS_PING
# Set DNS Name to keycloak-headless service
- name: JGROUPS_DISCOVERY_PROPERTIES
value: "dns_query=keycloak-headless.keycloak.svc.cluster.local"
- name: CACHE_OWNERS_COUNT
value: '2'
- name: CACHE_OWNERS_AUTH_SESSIONS_COUNT
value: '2'
# Allows use of a LoadBalancer
- name: PROXY_ADDRESS_FORWARDING
value: "true"
volumeMounts:
- name: startup
mountPath: "/opt/jboss/startup-scripts"
readOnly: true
volumes:
- name: startup
configMap:
name: keycloak-startup
defaultMode: 0555
...
# configmap.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: keycloak-startup
data:
keycloak-startup.cli: |
embed-server --server-config=standalone-ha.xml --std-out=echo
batch
echo * Setting CACHE_OWNERS to "${env.CACHE_OWNERS}" in all cache-containers
/subsystem=infinispan/cache-container=keycloak/distributed-cache=sessions:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=authenticationSessions:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=actionTokens:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=offlineSessions:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=clientSessions:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=offlineClientSessions:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
/subsystem=infinispan/cache-container=keycloak/distributed-cache=loginFailures:write-attribute(name=owners, value=${env.CACHE_OWNERS:1})
run-batch
stop-embedded-server
With these settings and configuration applied, you should see in the logs that your Keycloak pods are aware of and talking to one another! Both pods own and share the cache so that when one dies, the other still has all of the internal cache data. The new pod is recreated, joins the cluster, and pulls its cache from the existing pod!
Architecture Diagram
Conclusion
TL;DR Keycloak needs to explicitly be made aware of other Keycloak instances (pods) it should be communicating with to share an internal cache that contains important data such as user authentication sessions. Let's use a Kubernetes Headless service to do that.
This implementation has been working for our Customer in production for almost a year now with absolutely no hiccups. With newer versions of Keycloak, there are other clustering solutions you can look into (KUBE_PING) that might work better for you or your organization. Thanks for reading!



